
Top 10 Software Architecture Patterns
“The best software architects are those who can draw a line between the dots and then convince everyone else that the dots actually do connect.”– Simon Brown.
Building robust software for a project is very similar to setting the foundation of a building – it needs the right architecture. For the same reason, at least 85% of CEOs, CTOs, CIOs, and senior and lead developers of IT organizations will adopt a cloud-native software architecture framework by 2025, as reported by Gartner.
However, they also need an architect who knows the drill. A software architect knows how to use software architecture patterns to simplify the translation of the components, elements, processes, and layers into a unique solution.
They ensure that the software systems are designed, developed, and deployed consistently and efficiently while adhering to the structure of the project, the company’s guidelines, and even cost restrictions.
While the architects know these problems, they often find themselves in a rut, which pattern would make it easier to solve these issues. In this blog, we’ll uncover some software architectural patterns that make it easier to solve these issues arising from familiar situations. When a certain kind of problem is solved by many developers in a similar way, and it is generally accepted that this way solves that problem well, it becomes a pattern. A pattern is therefore something that addresses a recurring design problem for which a general solution is known among experienced practitioners: a pattern documents existing design solutions that have proved their worth. By writing a pattern, it becomes easier to reuse the solution.
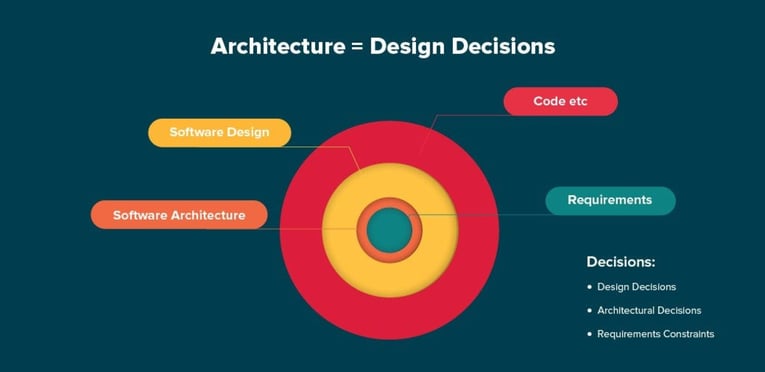
But before we dive into the most known architectural patterns, what is the difference between design patterns and architectural patterns?
Design patterns offer a common solution for a common problem in the form of classes working together. They are smaller in scale than architectural patterns, where the components are subsystems rather than classes.
Design patterns do not influence the fundamental structure of a software system. They only affect a single subsystem. Design patterns may help to implement an architectural pattern. For example, the Observer pattern (a design pattern) is helpful when implementing a system according to the MVC architectural pattern.
Architectural patterns are seen as commonality at higher level than design patterns. Architectural patterns are high-level strategies that concerns large-scale components, the global properties and mechanisms of a system.
Why should we focus more on Software Architecture?
A software development team makes the first set of decisions during the software architecture pattern selection. Only the business requirements are available before this stage. The first set of decisions are crucial in any project since sub-optimal decisions might result in budget and schedule overrun.
Your business stakeholders need to know about your progress. Software architecture acts as a visual communication tool, therefore they can understand the system you are building.
Software architecture models make it easy to reuse them in other projects since you now know the decisions you made and the various trade-offs.
What is a Software Architecture Pattern?
Software architecture patterns are reusable designs that can be utilized for figuring out solutions for different situations arising in the lifecycle of software development.
For example, Amazon once struggled to handle a large volume of traffic and responding in real-time became a big obstacle. They took a second look at their architecture and chose event-driven architecture. It allowed them to build loosely coupled systems and created a sync between their communications.
A software architecture is a combination of individual components and designs that make up the entire software. Hence, software architecture patterns are the principles that define the structure, interaction of components, and composition of programs.
A pattern defines the following two crucial aspects of a software project:
Easily understandable syntax and structure – which is the system design and application architecture.
A clean technical documentation that explains and visualizes the processes, invisible in the code.
Different Types of Software Architecture Patterns
Software architecture patterns are a blend of science and art. Today, software engineering offers diverse architectural patterns adaptable according to managing applications. They help project managers and business individuals select patterns aligning with quality attributes and functionalities.
Whether you’re launching an IT application or managing the IT infrastructure, we have listed the following top 10 architecture patterns to help you choose the appropriate one for building a robust system.
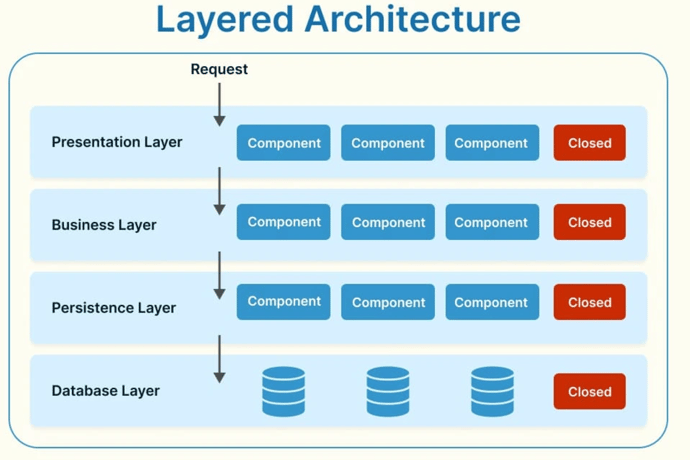
1.Layered Architecture
As the name suggests, this type of architecture has an “n” number of layers, and for the same reasons, it’s also called n-tier architecture. Each layer of the architecture has to perform a specific role and is organized into horizontal layers. The most common layers are the business layer, presentation layer, persistence layer, and database layers.
The business layer is responsible for executing specific business rules for a request. Similarly, the presentation layer overlooks all the communication happening in the browsers and user interfaces. The persistence layer handles the functions and data persistence. And finally, the database layer stores and retrieves data.
When building applications, understanding the difference between persistence logic and business logic is crucial for maintaining clean, maintainable, and scalable code.
1. What is Business Logic?
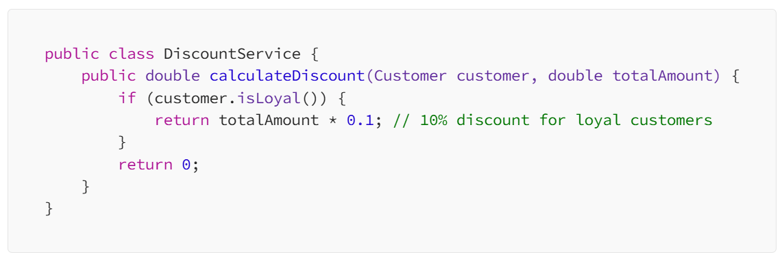
Business logic refers to the core operations of an application that implement specific business rules, decision-making, and calculations. It’s the part of your application that processes data according to the business requirements, like validating user inputs, calculating discounts, or determining whether a user has sufficient access rights.
Example of Business Logic:
Let’s say you’re building an e-commerce application. One key business rule could be calculating a discount for loyal customers:
In this example, the logic of determining whether a customer is loyal and calculating a discount is the business logic.
2. What is Persistence Logic?
Persistence logic is the part of your application responsible for saving, retrieving, updating, and deleting data from storage (usually a database). Its primary goal is to manage the flow of data between the application and the database. Unlike business logic, persistence logic doesn’t deal with business rules; it focuses on ensuring data is stored and retrieved efficiently.
Example of Persistence Logic:
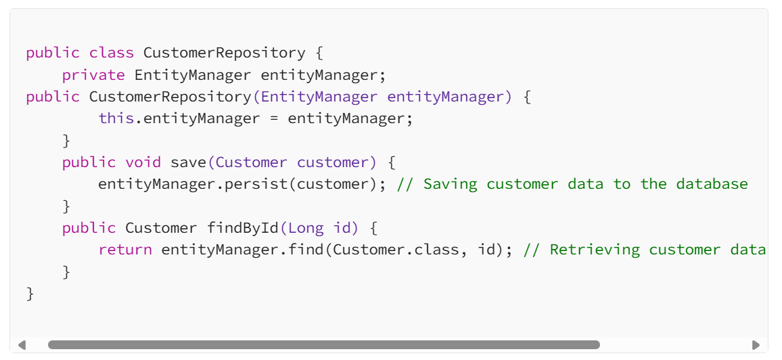
Continuing with the e-commerce example, here’s how you would save customer information into a database:
This class handles the persistence of the Customer entity. Notice how this doesn’t involve any business decisions like loyalty status or discounts; it merely focuses on saving and retrieving data.
3. Why Separating Business Logic from Persistence Logic is Important?
Mixing business logic with persistence logic can lead to several issues:
Complexity: Your code becomes harder to read and maintain. Business rules get tangled with database operations, making both harder to manage.
Testability: When your business logic and persistence logic are separated, you can test them independently. This leads to faster, more reliable tests.
Scalability: As the application grows, keeping these concerns separate helps scale features and infrastructure independently.
Separation of Concerns is a key principle in software design. It ensures that each part of your system focuses on a specific responsibility. In this case, business logic focuses on what the application does, and persistence logic focuses on how the data is stored.
4. How to Properly Separate Persistence Logic from Business Logic
Using a design pattern like Repository Pattern or frameworks like Spring Data JPA can help you cleanly separate business and persistence logic. Below is an example of how to keep the layers separate using these patterns.
Refactoring Example:
Business Logic in Service Layer:
Persistence Logic in Repository Layer:
In this case, the OrderService focuses purely on business logic, like calculating the discount, while the CustomerRepository focuses on saving and retrieving data from the database.
5. Benefits of Separating Persistence and Business Logic
Maintainability: When business rules change, you only modify the service layer. Your database operations remain untouched, improving maintainability.
Flexibility: You can switch databases or modify how data is stored without touching business logic.
Reusability: Business logic can be reused in multiple parts of your application, independent of how the data is persisted.
6. Common Mistakes to Avoid
Mixing Logic: Adding database queries within business logic (e.g., directly fetching entities in the service layer).
Over-Complicating: While separation is important, avoid over-engineering the solution with too many layers or patterns that aren’t necessary for the application size.
Conclusion
In summary, business logic and persistence logic serve distinct purposes in an application, and it’s crucial to keep them separate. Business logic governs how your application behaves according to its requirements, while persistence logic ensures your data is stored and retrieved correctly. By keeping these two layers separate, you improve the maintainability, scalability, and testability of your application.
Understanding and applying this distinction will help you write cleaner, more efficient, and scalable code.
Key Takeaways:
Business Logic: Focuses on decision-making, validation, and implementing business rules.
Persistence Logic: Handles saving and retrieving data from a database.
Separation of Concerns: Essential for maintainability and scalability in software design.
By mastering the separation of persistence logic and business logic, you’ll create applications that are easier to maintain, test, and extend as they grow.
Benefits of Layered Architecture:
Scalability, you can separate tiers without affecting the other tiers and then scale each one properly.
Data Integrity, Cascading effects are prevented, and maintenance becomes easier. One may change the code without affecting the data.
Re-usability, Different layers could be used in different projects or in the same project you may use the same layer in different places. For instance, you might want to write extensions to your projects and if you want to use them in another project
Secure, you can secure the layers without affecting the other layers.
Ideal For/When:
Need quick app development
Traditional IT infrastructure and processes
Apps requiring separate concerns and long-term maintenance
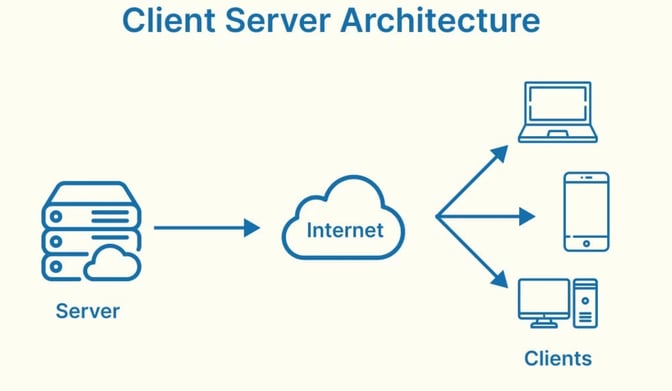
2.Cient -Server Architecture
The two main components of this type of architecture are the client i.e., the user, and the server, i.e the service provider. The responsibility of the server layer is to pay attention to the requests from the client’s components. Then, it processes the request, after which it sends a response back to the client.
The server can be categorized into stateful or stateless. The client component begins interaction with the server to get the required services. Both servers and the client components are connected by a common link called response connectors.
For a "stateful server", the client-server component makes the connection by storing a record of each request from the client, also known as sessions.
For a "stateless service", it doesn't persist any information between client sessions. They restore their state for each new session, using information provided by the client. Stateless architecture is particularly ideal for authorization systems. ( Importance of Stateless Architecture in Authorizations System. )
Stateful vs Stateless Architecture – Explained for Beginners
Characteristics of this pattern:
Client components send requests to the server, which processes them and responds back.
When a server accepts a request from a client, it opens a connection with the client over a specific protocol.
Servers can be stateful or stateless. A stateful server can receive multiple requests from clients. It maintains a record of requests from the client, and this record is called a ‘session’.
Benefits Of Client Server Architecture
Data integrity, Clients access data from a server using authorized access, which improves the sharing of data.
Easiness, Accessing a service is via a ‘user interface’ (UI), therefore, there’s no need to run terminal sessions or command prompts.
Independent, Client-server applications can be built irrespective of the platform or technology stack.
Maintainability, this is a distributed model with specific responsibilities for each component, which makes maintenance easier.
Drawbacks
The server can be overloaded when there are too many requests.
A central server to support multiple clients represents a ‘single point of failure’.
Ideal For/When:
Apps requiring centralized data management
Database apps with high data integrity and security
Web apps where the server manages data and requests









Inspire
Let's Build the Future
Create
youngcrittersacademy@gmail.com
+1 408-768-1983
© 2024. All rights reserved.